
VIO快速入门(一):从最小二乘开始
最小二乘法
一个简单的例子
假设现在你在调试一个超声波测距仪,你将其放置在一个固定的位置,想测量其到墙壁的距离。由于各种误差的存在,这个测距仪每次读出来的数据都是在真值附近波动的不同的值:10.5m、10.2m、9.7m、9.4m、11.4514m、9.8m……。那么应该如何从这些量测中计算出一个与真实距离最接近的值呢?现在有$n$个量测,每个单独的量测记为$z_i$,如果能找到一个值,使得这个值与各个量测之间的偏差之和最小,那么可以认为这个值就是待估计的真值$x^*$了。把上面的想法转换为代数形式即为
注意到,$F(x)$是一个二次函数,当其导数为0时其取得最小值。因此通过解下面的方程即可求得我们想要的真值$x$
那么上面的这个方法其实就是最小二乘法。因为在这个过程中我们需要求一个最小值,这个算法也是优化算法的一种。实际上对这个简单的一维的例子而言,真值$x$正好是算数平均数。下面给出最小二乘法问题的一个标准定义:找到一个$n$维的变量$\boldsymbol x^*$,使得损失函数$\boldsymbol F(\boldsymbol x)$取得最小值。其代数形式为
其中
$\boldsymbol{x}$为优化变量;$\boldsymbol r_i$为残差函数,它反映了量测值与预测值之间的差,并且有$m\ge n$。这里的局部最小值指的是对任意$||\boldsymbol x-\boldsymbol x^*||<\delta$,有$\boldsymbol F(\boldsymbol x^*)\le\boldsymbol F(\boldsymbol x)$。需要注意的是,残差函数在很多情况下不一定是线性的,也即从优化变量$\boldsymbol x$到预测值之间需要经过一个非线性的变换关系$\boldsymbol h(\boldsymbol x)$,然后才能与量测值作差来构建残差。对线性的残差函数我们可以直接使用线性最小二乘求解,通过求损失函数的极小值点即可得到$\boldsymbol x^*$。而对于非线性的残差函数,则需要将其在某个点处进行线性化后使用迭代下降法求解。
非线性最小二乘的求解
迭代法的核心思想非常简单,就是找一个下降方向使损失函数随$\boldsymbol x$的迭代逐渐减小,直到$\boldsymbol x$收敛到$\boldsymbol x^*$。下面介绍一个经典的迭代法:高斯-牛顿(Gauss-Newton)法。首先,为了形式的简洁,可以将残差组合成向量的形式
那么,损失函数可以写为
之后,对非线性的残差函数在$\boldsymbol x$处做一阶泰勒展开可得
其中$\boldsymbol J$为残差函数的雅可比矩阵。将上面线性化后的残差函数代入损失函数,有
这样损失函数就近似成了一个二次函数,并且如果雅可比矩阵是满秩的,那么$\boldsymbol J^\top\boldsymbol J$是正定的,损失函数有最小值。另外,在点$\boldsymbol x$处对$\boldsymbol F(\boldsymbol x)$做二阶泰勒展开有
其中$\boldsymbol F^{'}(\boldsymbol x)$为$\boldsymbol F(\boldsymbol x)$对$\boldsymbol x$的雅可比矩阵,$\boldsymbol F^{''}(\boldsymbol x)$为$\boldsymbol F(\boldsymbol x)$对$\boldsymbol x$的Hessian矩阵,$\boldsymbol R$为高阶项。与前面的式子对比,可以知道
对$\boldsymbol L(\Delta \boldsymbol x)$求一阶导并令其等于零,有
可以得到
上面这个方程被称为Normal Equation或者增量方程,
它也可以被简写为$\boldsymbol H\Delta\boldsymbol x=\boldsymbol b$或者$\boldsymbol\Lambda\Delta\boldsymbol x=\boldsymbol b$的形式。
需要注意这种简写的形式在之后会经常出现。高斯牛顿法的主要步骤如下:
- 给定初始值$\boldsymbol x_0$;
- 对第$k$次迭代,计算出$\boldsymbol x_k$处的$\boldsymbol H$和$\boldsymbol b$,并求解增量方程;
- 若$\Delta \boldsymbol x$足够小则认为算法收敛,否则令$\boldsymbol x_{k+1}=\boldsymbol x_k+\Delta\boldsymbol x$并返回第2步。
但是在实际情况中,$\boldsymbol H$矩阵不一定就是正定的。因此,可以引入阻尼因子,此时增量方程变为
注意这里$\mu>0$,这样可以保证$\boldsymbol H$矩阵是正定的,迭代可以沿着下降方向进行。这种方法被称为Levenberg-Marquardt法。LM法相比GN法还有其他的一些改进,但优化算法不是这里的主题,因此就不过多介绍了。
最大后验估计与最小二乘
回到一开始的那个测量距离的例子。我们关注的是从量测中估计出真值,而在测量时由于噪声的存在,量测$\boldsymbol z_i$和真值$\boldsymbol x$服从后验概率分布$p(\boldsymbol x|\boldsymbol z_i)$。在多次测量时,各个量测相互独立,那么多个量测构成的后验概率分布为
然后,可以通过最大后验估计来求得使得这些量测出现概率最大的真值
在上面的公式中,第二行由贝叶斯公式推导而来。在第三行中,由于我们关心的是$\boldsymbol{x}$,所以分母中的$p(\boldsymbol{z})$可以丢掉。对目标函数取对数,可得
在开头的测量距离的例子下,$p(\boldsymbol x)$可以近似为常数。因此
假设有量测模型
其中$\boldsymbol n$为噪声,服从均值为零的多维高斯分布$N(0,\boldsymbol \Sigma)$,$\boldsymbol \Sigma$为协方差矩阵。进而,我们可以认为在真值为$\boldsymbol x$的条件下出现量测$\boldsymbol z_i$的概率等价于噪声在该次测量中等于$\boldsymbol n_i$的概率,也即
因此,之前的最大似然估计问题变为
又因为
且有残差$\boldsymbol r_i=\boldsymbol x -\boldsymbol z_i$,所以最大似然估计问题可以等价为
这刚好就是一个最小二乘问题。其中范数$||\cdot||^2_{\boldsymbol\Sigma}$称为马氏距离。这个最小二乘问题同样可以通过解下面的增量方程来解决
这里$\boldsymbol \Sigma^{-1}$也被称为信息矩阵。关于此处多出来的这个信息矩阵,可以从概率的角度理解,也可以从权重的角度理解。例如在优化变量中某个分量测量的噪声特别大,那么它的方差就会很大,在信息矩阵中与其相应的项就会小。这相当于减小了这个分量在优化问题中的权重,防止其他分量被这个变量噪声带偏,保证整个优化问题可以有一个比较好的效果。在实际的VIO问题中,损失函数中使用的也是残差的马氏距离。
注意,为了便于理解,这里假设了先验$p(\boldsymbol x)$可以忽略,问题实际上从最大后验估计变成了最大似然估计。如果先验不能忽略,那么它会在最小二乘中变成一个额外的先验残差项。
VIO问题构造
从惯导到VIO
惯性导航依赖惯性测量元件(IMU)——加速度计和陀螺仪——来对载体进行定位,其原理其实十分简单:在载体静止的状态下,惯导通过人工输入的一个坐标进行初始化,在这之后通过对测量得到的加速度进行积分可以得到载体的速度,再对速度积分就可以得到载体的位置;对角速度积分可以得到角度,进而得到载体的姿态。
虽然这个理论非常简单,但是由于各种噪声的存在,在实际的工程应用中想要达到比较高的精度,惯导设备的体积十分巨大,结构和算法十分复杂,价格十分昂贵。但是在消费级产品中,处于成本、重量、体积的考虑,基本都是使用MEMS元器件组成IMU。但是,这些微小的元件噪声比较大,受温度的影响比较显著,纯惯导算法基于它们的数据计算一段时间后就会产生很大的漂移,几乎无法使用。
那么有什么办法可以解决这个问题呢?除了提高IMU本身的精度,还可以通过引入外部信息的方式来减小漂移。例如,经典的GNSS与IMU组合导航算法,这个算法将GNSS的信息与IMU的信息融合,以此来补偿IMU的误差。本身这种算法已经具有比较高的精度了,然而在现在的使用场景中,GNSS拒止是非常常见的情况。于是,各种将IMU信息与不依赖外部基础设施的传感器的信息融合的算法出现了,这些传感器有轮速计、气压计、磁罗盘、激光雷达、深度计等。当然,还有视觉信息。实际上,纯视觉也是可以进行定位的。下面的表格给出了纯IMU定位与纯视觉定位方案的优劣对比:
| 方案 | IMU | 视觉 |
|---|---|---|
| Pros | 响应快,不受外界环境影响,角速度比较准确,可估计绝对尺度 | 不会漂移,可以直接测量旋转与平移 |
| Cons | 存在零偏,精度与价格和体积无法兼得 | 容易受外部环境(遮挡、运动物体、气象条件)干扰,单目视觉无法测量尺度,单目无法估计纯旋转运动,快速运动时易丢失 |
通过上面的表格可以看出,IMU与视觉方案具有一定的互补性质:IMU适合处理短时间、快速的运动,而视觉则与之相反。同时,可以使用视觉定位信息估计IMU的零偏,减少零偏导致的发散和累积误差,另外IMU也可以为视觉提供快速运动时的定位。
那么,视觉信息是如何与IMU信息进行融合的呢?下图展示了视觉与IMU紧耦合的方案:
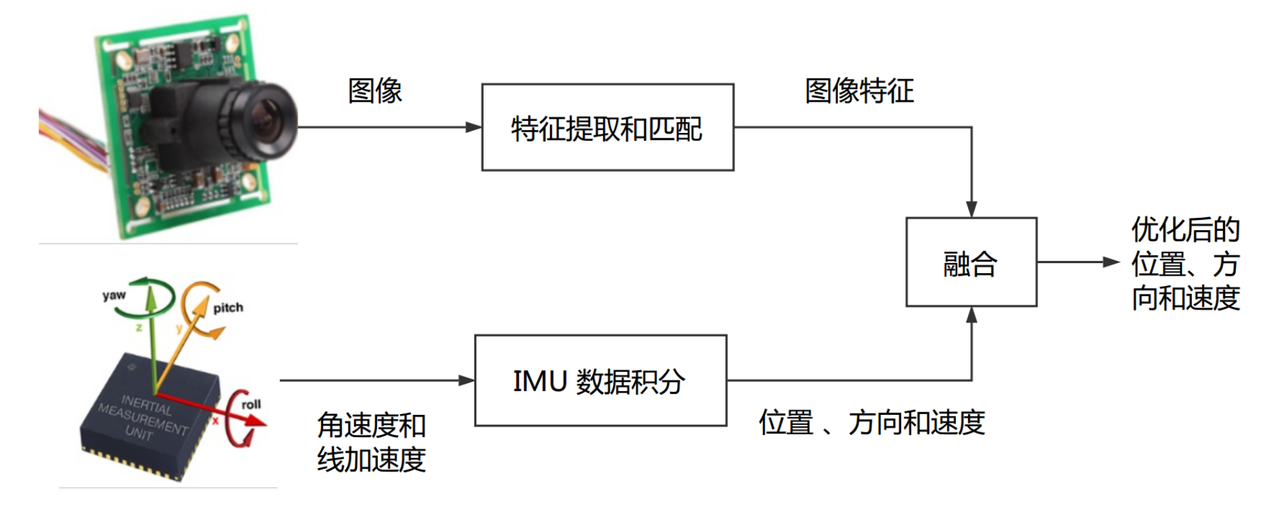
而与之对应的,松耦合的方案就是先根据图像特征计算出位姿估计,再将这些信息与IMU的位置、方向、速度等进行融合。与紧耦合相比,松耦合的融合算法相对比较简单。但是,紧耦合可以一次性建模所有的运动和测量信息,更容易达到最优。因此,目前主流的VIO算法(包括VINS)都采用的是紧耦合的算法。
根据上图,我们可以总结出VIO算法的大致流程。首先,视觉部分的相机采集到图像之后,图像处理算法提取到特征点并在多帧图像之间完成特征点的匹配;然后IMU采集到高频率的线加速度和角速度数据,通过积分求得图像帧拍摄时刻的载体的位置、姿态、速度;最后,使用融合算法将前端得到的特征点与IMU得到的位置、姿态、速度进行融合,求得优化后的位置、姿态、速度。因为这个算法是根据视觉信息与惯性信息求解得到位姿信息,所以它就被称为视觉-惯性里程计,也即Visual-Inertial Odometry (VIO)。其中,视觉特征点提取与IMU积分属于前端,而数据的融合与优化属于后端。
这里补充讲解一下VIO与(视觉)SLAM的关系。根据定义,SLAM (Simultaneous Localization And Mapping) 的含义为:载体从未知环境的未知地点出发,在运动过程中通过重复观测到的地图特征定位自身位置和姿态,再根据自身位置增量式的构建地图,从而达到同时定位和地图构建的目的。由于VIO不涉及建图的过程,因此它其实可以算是SLAM的一个子集。
VIO的目标函数
下面这张图展示了一个小规模的VIO问题的形式:
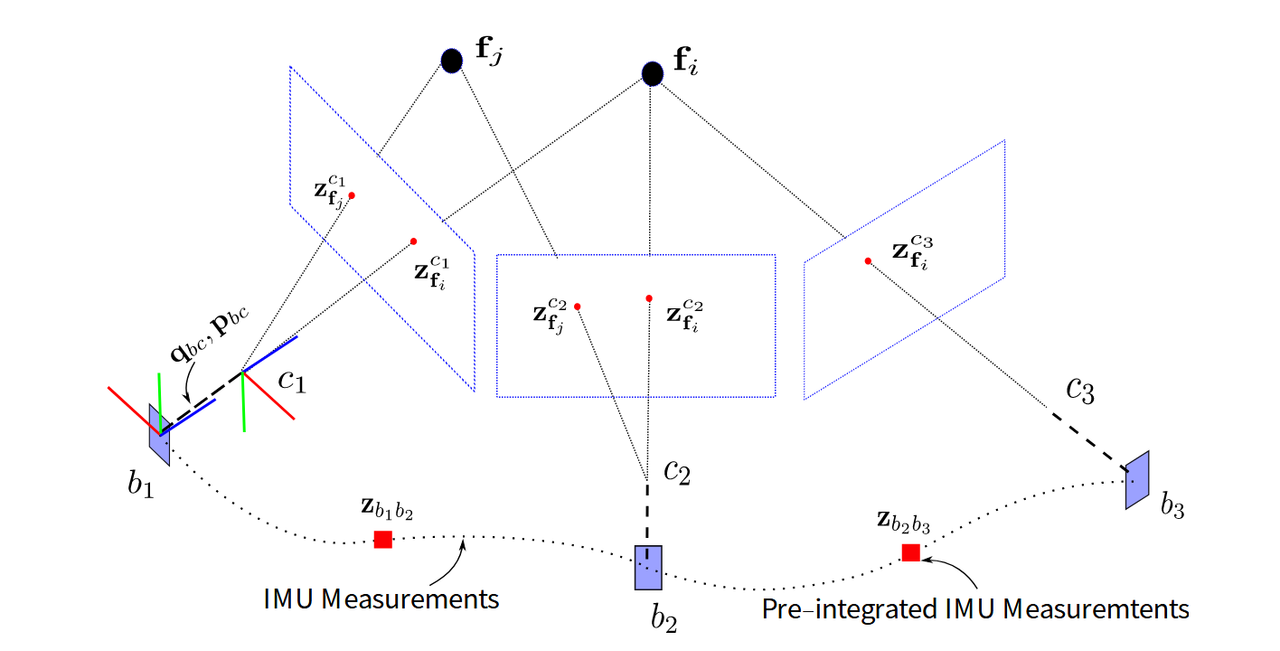
图中,$c_1$、$c_2$、$c_3$代表拍摄3帧图像时的相机;$b_1$、$b_2$、$b_3$为拍摄相应图像时的IMU;IMU坐标系和相机坐标系之间存在一个已知的旋转变换$\mathbf{q} _{bc}$和平移变换$\mathbf{p}_{bc}$;黑色小点代表IMU的量测;红色方块$\mathbf{z}_{b_ib_j}$代表两帧之间IMU积分出来的位置、姿态、速度的增量;$\mathbf{f}_i$、$\mathbf f_j$代表三维空间中的路标点,在某个位置上的路标点是唯一的,一个路标点对应着各帧中不同的特征点;$\mathbf{z}_{\mathbf f}^c$代表投影到相机成像平面上的路标点对应的特征点的二维坐标。
我们目前有的量测是IMU积分得到的帧间位姿增量$\boldsymbol z_{b_ib_j}$与相机拍摄到的特征点坐标$\mathbf{z}_{\mathbf f}^c$,然后我们想求出各帧图像所对应的IMU的位置$\mathbf{p}$、速度$\mathbf{v}$、姿态$\mathbf{q}$。假如我们知道相机在两帧的$\mathbf{p}$、$\mathbf{q}$以及路标点在三维空间中到相机的距离(也即深度)$1/\lambda$,我们就可以根据路标点在第一帧中的二维坐标$\mathbf{z}_{\mathbf f}^{c_1}$,经过一系列投影变换后,估计出其在第二帧中的二维坐标$\mathbf{z}_{\mathbf f}^{c_2}$。注意到,我们刚好有这样的一个量测,因此可以构建一个估计与量测的残差,这个残差也叫重投影误差。类似的,假如我们知道相机在两帧的$\mathbf{p}$、$\mathbf{q}$,那么我们也可以建立它们与$\mathbf{z}_{b_ib_j}$的残差。将上面这些“我们假设自己知道的变量”作为优化变量,结合多个量测,就可以构建一个以最小化残差为目标函数的最优化问题,求解该问题即可得到我们想求出的各个物理量。
当然,在实际的VIO中优化问题比上面的描述还是要复杂一些,但核心思想是一样的。下面给出实际的VIO算法(以VINS-Mono为例)中构造的优化问题。这个优化问题的目标函数为
为了节约计算量,只有一段时间内图像帧的位姿会被优化,这种方式被称为滑动窗口优化。这些参与优化的,在滑动窗口中的图像帧被称为关键帧。式子中,$B$代表关键帧的集合;$F$为特征点的集合;$\mathcal{X}$为优化变量;$\mathbf r$为残差函数;$\boldsymbol\Sigma$为残差项对应的协方差矩阵;$\hat{\cdot}$代表量测;$\rho$为用于提高优化算法效果的核函数。优化变量的定义如下
其中,$n$为滑动窗口中第一个关键帧的索引;$N$为滑动窗口中关键帧的数量;$m$为关键帧中第一个特征点的索引;$M$为滑动窗口中所有特征点的数量;$\mathbf{p}_{b_i}^w$为第$i$帧(IMU坐标系相对于世界坐标系的)的位置;$\mathbf{q}_{b_i}^w$为第$i$帧(IMU坐标系相对于世界坐标系的)的姿态四元数;$\mathbf{v}_{b_i}^w$为第$i$帧(IMU坐标系相对于世界坐标系的)的速度;$\mathbf b_a$为加速度计的零偏;$\mathbf b_g$为陀螺仪的零偏;$\mathbf p^b_c$为相机坐标系到IMU坐标系的位移,$\mathbf q^b_c$为相机坐标系到IMU坐标系的旋转变换四元数,它们两个组合成了外参$\mathbf x_c^b$;$1/\lambda_m$为特征点的深度。
观察这个式子可知它由三部分组成:
- 先验残差:这部分由被移出滑窗的关键帧的信息构成,之后会介绍;
- IMU残差:这部分根据IMU积分出的帧间位置、姿态、速度的增量构造;
- 视觉残差:这部分就是特征点的重投影误差。
求解此非线性优化问题即可得到我们想要的位置、速度、姿态。
前面提到过,求解非线性优化问题的核心在于求解增量方程。那么增量方程中的雅可比矩阵$\boldsymbol J$和协方差矩阵$\boldsymbol \Sigma$如何计算?残差$\boldsymbol r$又如何构造呢?下一篇文章将详细介绍这部分内容。
附:关于贝叶斯公式
首先给出贝叶斯公式的基本形式。已知有事件$A$和事件$B$,我们想要知道在事件$B$发生的条件下,事件$A$发生的概率(由结果推导原因),可以通过下面的公式计算
对公式中的几个概率的解释如下:
- $P(A)$:先验概率,可以理解为在看到新证据$B$之前,对事件$A$发生概率的基础认知;
- $P(B|A)$:似然,可以理解为假设事件$A$真的发生了,出现证据$B$的概率有多大;
- $P(B)$:可以理解为不管事件$A$到底有没有发生,这个新证据$B$发生的总概率;
- $P(A|B)$:后验概率,可以理解为代表看到新证据之后更新的认知。
贝叶斯公式可以通过下面的关系简单地得到
VIO快速入门(一):从最小二乘开始