
CS106L总结与C++的一些新特性
这篇文章主要根据Stanford CS106L课程中的内容,对之前的博客Accelerated C++笔记进行一些补充
auto关键字
auto意味着由编译器自动推断出类型,如果对象的类型是什么不太重要时,可以使用auto- 一些使用场景:
- 在声明某个容器的迭代器时使用
auto可以避免输入冗长的类型 - 在可以根据上下文简单推断出对象类型时(如模板类中或者使用拷贝构造函数、拷贝赋值函数时)
- 在lambda函数中
- 在声明某个容器的迭代器时使用
- 不能随便使用
auto(例如对函数返回值类型不能简单用auto替代,会降低可读性,像auto a;这种使用方法也是非法的) - 在使用
auto拷贝对象时,会丢弃被拷贝对象原本的const或者引用属性,所以如果想保留这些属性的话必须将const或者&与auto结合使用
std::pair与结构绑定
std::pair用于将两个任意类型的对象绑定起来- 声明与初始化:
std::pair<T1, T2> p = {field1, field2}; - 使用
p.first和p.second来访问pair中的对象 - 可以使用
std::make_pair(field1, field2)来构造一个pair - 可以使用
pair作函数返回值,同时返回函数状态(成功?/失败?)以及需要的结果(值)
- 声明与初始化:
- 结构绑定:直接使用
auto+中括号获取pair中的内容,例如对上面声明的p,可以这样获得其中的内容:auto [field1, field2] = pair;
关于stream的更多知识
stream是对输入和输出的抽象,用于将数据和字符串之间互相转换- 关于输出流:
<<操作符将对象转换为字符串保存在缓冲区,然后在遇到std::endl时一起输出 - 在之前的文章中提到过
std::getline(istream& stream, std::string& string)的用法,不要和>>混用 - 关于流的状态位:
- Good bit:
std::ios_base::goodbit,准备好读/写 - Fail bit:
std::ios_base::failbit,上一次操作失败(例如要求读入一个int却收到了一个char),后续的操作都会被冻结 - EOF bit:
std::ios_base::eofbit,上一次操作到达缓冲区的结尾(例如cin遇到了空格或EOF) - Bad bit:
std::ios_base::badbit,外部错误,大概率不可恢复(例如正在读的文件突然被删除) - G/F、G/E状态位是可以同时出现的,通常需要检查F/E状态位
- Good bit:
- 注意
std::cin不要和>>一起使用:std::cin按行读入缓冲区但>>用空格将其分段- 缓冲区的垃圾值会让
std::cin不提示用户开始输入 std::cin的F状态位开启后后续操作全部失效
- 关于
stringstreams- 使用
stringstrems之前要先定义对象,如:std::istringstream iss("blah blah");,std::ostringstream oss("blah blah"); std::istringstream:将任何类型数据存储为std::string,在与>>一起使用时会根据对象类型进行拆分std::ostringstream:将任何类型的数据转为字符串输出,使用oss.str()方法进行转换
- 使用
通用初始化与std::initializer_list
- 通用初始化(Uniform Initialization)可以用于初始化非内置类型,如假设有一个自定义类
Student,那么可以使用Student s{"Yaju", "JP", 24};的方式初始化 - 通用初始化可以嵌套使用
std::initializer_list可以用于接受含有同种类型元素的列表,只能被整体初始化或者赋值- 对于自定义类
Student,若其定义了接受std::initializer_list的拷贝构造函数,可以通过这种方式进行初始化:Student stu = {"Yaju", "JP", 24}; - 也可以使用
std::initializer_list传递函数参数
- 对于自定义类
STL序列容器对比
这里主要是对比一下std::vector、std::deque、std::list几个序列容器:
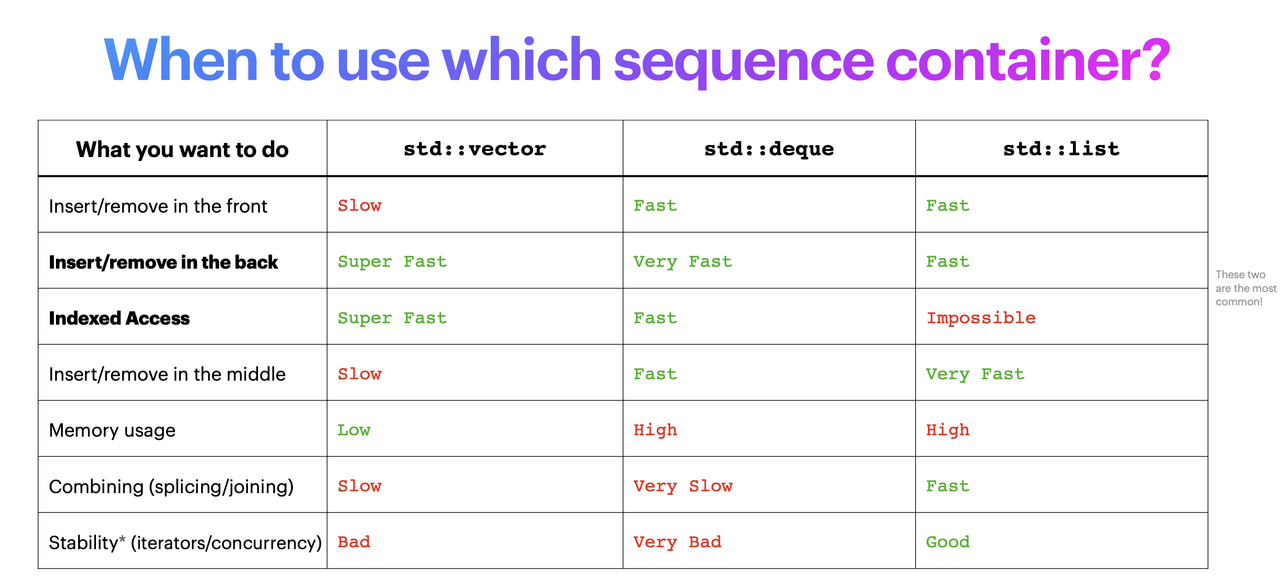
std::vector:向量std::list:双向链表std::deque:双向队列,有下标顺序容器,允许其在首位两端快速插入/删除
绝大部分情况下用std::vector就可以了。
#include “xxx.cpp”的作用以及编译过程
在CS106L的课程中,是在模板类中涉及到#include "xxx.cpp"这样的操作。通常情况下,模板类的声明和定义只能写在头文件中,而不能像非模板类那样讲声明写在头文件中,将定义写在源文件中,然后再在源文件中include头文件。但是如果一定要分离模板类的声明和定义,可以使用头文件include源文件的形式。不过这样只是在代码层面将两者分离,不会对编译过程有任何帮助,所以一般没有必要。
一般需要引入.cpp文件的原因有两个:
- 把代码内一些写死的复杂数据拆分出来,单独放入一个源文件,看起来更整洁
- 将
.cpp文件全部include之后有助于编译器对代码的优化
下面给出编译过程:
- 预编译:输入
.cpp+.h,展开头文件、宏定义、内联函数等 - 编译:输入
.i,得到汇编代码 - 汇编:输入
.s,将汇编指令转为机器码 - 链接:输入
.o(二进制文件),将其与各个库进行链接,确定函数定义和全局变量的位置 - 最后得到可执行文件
.exe
using、typedef及其作用域
- 定义一般类型的别名时没有区别,定义模板的别名只能用
using - 通常使用
using就可以了 using是局部的,其作用域为从using声明开始,直到包含其声明的作用域结尾
范围for循环
对于一个容器,使用其迭代器自动迭代:
1 | std::vector<int> vec{1, 2, 3, 4, 5}; |
- 如果需要修改容器中的值,需要对范围
for中的迭代器声明为引用类型auto& - 在循环体中,
it直接是解引用后的 - 对任何容器,想要使用范围
for,必须具备以下属性:- 具有
begin和end方法 - 迭代器支持操作符
*、!、=、++(前缀)
- 具有
运算符重载与仿函数(functor)
在类中,作为成员函数的重载运算符的左操作数默认为
this,且只能从对象左边被调用非成员函数的重载运算符若需要访问类的私有成员,可以将其声明为
friend仿函数(functor):重载
()运算符的类,也叫函数对象通过使用对象维护某些操作中重复出现的值,使语法更加简洁
可以在函数中调用这个仿函数对象来进行特定的操作,使用仿函数(本质是一个类的实例)时的方法就像使用函数一样,调用仿函数的函数负责为仿函数提供需要的参数
仿函数的功能可以使用函数指针实现,他们都是另一个函数的参数
lambda表达式
- lambda表达式可以用于替代仿函数与函数指针
- 其形式为
1 | type_name func_name = [outside_vars](type_name parameter)->return_type {body} |
- 捕获列表:
[]运算符表示接下来的代码是lambda函数,用于捕获上下文中的变量供lambda表达式使用[]表示不捕获任何变量[var]、[&var]分别表示通过值/引用传递捕获变量[=]、[&]分别表示通过值传递或者引用传递方式捕获所用父作用域的变量- 捕获列表中通过值传递的变量默认是不能在lambda函数中修改的,但是可以通过在函数体前面加上
mutable关键字来使其可以被修改
- 参数列表:用于声明函数体中需要用到的参数及其类型
- 返回值是可选的
for_each
for_each是一种另一种循环的语义- 其形式为:
for_each(InputIter first, InputIter last, UnaryFunction) {body} - 第一、二个参数是容器的迭代器,分别指向需要操作的元素范围的起点和终点
- 第三个参数可以接受
std::function,包括函数指针或其引用、仿函数、lambda表达式
Special member functions
对于一个类A,共有6个:
默认构造函数:
A() {};拷贝构造函数:
A(const A& other);拷贝构造函数使用另一个对象对一个对象初始化,其中成员变量要全部复制到被初始化的那个对象中
拷贝赋值函数:
A& operator=(const A& rhs)函数返回值为引用以实现连续赋值,在函数体中要判断
this指针是不就是rhs以防止自我赋值,需要先释放对象中原来保存的资源移动构造函数:
A(A&& other);函数参数不能是
const的且必须把右值的内容更改掉,函数内部均使用std::move进行赋值移动赋值函数:
A& operator=(A&& rhs)需要判断是否是自我赋值,其他与移动构造函数一致
析构函数:
~A() {};
深拷贝与浅拷贝
- 浅拷贝:基本数据类型、简单的类使用浅拷贝即可,就是将
rhs内存中的数据直接拷贝到lhs中 - 深拷贝:如果某个类内部有动态分配的内存或者指向其他数据的指针,那么对该类的两个对象就不能简单的直接进行拷贝赋值,否则两个类中的内存或指针将指向同一个区域,深拷贝就是将
rhs中持有的内存中的数据同样拷贝一遍,这样可以做到原有对象和新对象中持有的内存是互相独立的
左/右值,左/右值引用
- 左值:有自己的内存,表达式结束后仍能存在的持久对象
- 右值:没有分配的内存,表达式结束后不再存在的临时对象,包括字面量(除字符外)与将亡值(临时的表达式的值,临时的函数返回值等)
- 字符字面量不是右值,因为它在静态存储区
- 左值引用
&:引用左值,深拷贝 - 右值引用
&&:引用右值,浅拷贝,对右值因为其不需要持续存在,所以在拷贝时可以直接将rhs中持有的内存给lhs而不需要再拷贝一次内存中的内容 const &同样可以接受右值
移动语义
- 对于之后不再继续使用的对象,可以在将其复制给其他对象时用
std::move强转右值,尤其是在复制体积较大的对象时 - 使用
std::move不会改变原对象的左右值属性,这就要求在对象的移动构造/赋值函数中手动释放原对象的资源
Rule of 4 (or 6, or 0)
- 在一个类中,如果你确实需要手动定义4个SMF(不包括移动构造和移动赋值函数,如果包括就是6个)中的任意一个,那么你就需要定义其余的SMF
- 如果默认的SMF能用,那么你不要自己定义SMF
std::optional
std::optional是一个模板类,其中可以含有某个类的值或者什么都没有(此时它是std::nullopt),它可以用来防止类成员函数中的某些未定义行为发生- 成员函数(接口):
value():返回其中保存的值或抛出bad_optional_access异常value_or():返回其中保存的值或默认值has_value():如果其中有值则返回true,否则返回false
RAII与智能指针
程序中发生的一些异常可能导致之前申请的动态内存没有被释放
RAII:Resource Acquisition Is Initialization,一个类的所有资源都应该在构造函数中申请,在析构函数中释放,这里的资源包括动态分配的内存、文件、锁等
针对内存而言,可以使用智能指针实现RAII使用智能指针避免显式使用
new、delete有三种智能指针:
std::unique_ptr:不能被复制,只有它自己能管理它所指向的资源,当它离开自己的作用域时它和它指向的资源都被释放,使用std::make_unique<T>()初始化,不能拷贝构造或拷贝赋值,但是可以进行移动构造或移动赋值std::shared_ptr:可以被复制,对一处内存,当所有std::shared_ptr都和它没关系时这块内存就会被释放,使用std::make_shared<T>()初始化,可以用于代替(计数)句柄类std::weak_ptr:可以临时控制资源,只能通过对std::shared_ptr拷贝赋值或移动赋值的方式初始化
例:
1
2
3std::unique_ptr<T> up = std::make_unique<T>();
std::shared_ptr<T> sp = std::make_shared<T>();
std::weak_ptr<T> wp = sp;
CS106L总结与C++的一些新特性