
DSA-4:向量及其接口设计2
向量的基本接口
引用元素
在向量类中,元素的访问方式就是通过下标。因此,可以在向量类中重载操作符[]来实现这个功能。向量的索引也就是其内部私有数组_elem[]的索引。该算法实现起来没有难度,但是要注意在重载的时候需要合理使用const修饰符来控制被访问元素的可更改性。
置乱器
在软件测试、仿真模拟等应用中,经常需要使用到随机向量。随机向量随机性的高低直接影响到测试的覆盖面大小与仿真结果的优劣。
向量中的置乱器unsort()就提供了生成随机向量的功能。该算法从待置乱区间的末元素开始,逆序地向前逐一处理各个元素。对每一个当前元素,都与随机生成的第rand() % i个不超过i的元素进行交换。经过每一步这样的处理,置乱区间就会向前拓展一个单元。经$\mathcal O (n)$次迭代后,实现整个向量的置乱。算法实现如下:
1 | template <typename T> void Vector<T>::unsort ( Rank lo, Rank hi ) { //等概率随机置乱区间[lo, hi) |
判等器与比较器
首先要分清两个概念:
- 判等:判断两个对象是否相等,亦被称为比对
- 比较:判断两个对象的相对大小
在上一篇文章中我们说过,在设计向量类时假设其中的元素都是可以互相比较大小的。因此对于向量中可能存储的元素类型T,我们需要针对其设计判等器与比较器。有两种方法可以用来实现判等器与比较器:
- 使用函数封装
- 重载关系比较操作符
判等器和比较器对有序向量来说至关重要,有序向量中的元素必须存在某种可以比较相对大小的关系才能称之为有序。
关于有序向量,我们约定其中的元素自前向后(秩由小到大)的元素构成一个非降序列。即对一向量$S[0, n)$,若有任意的秩$i, j$满足$0 \le i < j < n$,有$S[i] \le S[j]$。
插入
插入函数需要首先调用expand()函数检查_elem[]是否即将溢出,在必要时对向量进行扩容。然后,为了保证向量(数组)元素的物理地址连续,需要将插入元素所在位置的后缀整体后移一个单元。在这之后,才能在目标位置置入对象并更新向量规模。算法实现如下:
1 | template <typename T> //将e作为秩为r元素插入 |
插入算法的时间消耗主要来源于后缀的后移,线性正比于后缀长度,因此其时间复杂度为$\mathcal O (\underline{}size - r +1)$。时间复杂度里的+ 1可以理解为插入元素操作需要的时间,其中包括置入元素与更新向量规模。当r = _size时为最好情况,需要$\mathcal O (1)$时间;r = 0时为最坏情况,需要$\mathcal O (\underline{} size)$时间。一般来说,若插入位置等概率分布,那么平均运行时间为$\mathcal O (\underline{}size) = \mathcal O (n)$。
删除
删除操作有两个接口:remove(lo, hi)用于删除区间[lo, hi)中的元素,remove(r)用于删除秩为r的单个元素。为了减少元素移动的次数,应当将删除单个元素的情形作为删除多个元素的情形的特例,基于后者来实现前者。
下面先给出了区间删除的代码:
1 | template <typename T> int Vector<T>::remove ( Rank lo, Rank hi ) { //删除区间[lo, hi) |
上面的代码无非就是将被删除区间直接使用其后缀覆盖,然后通过调整_size的值直接丢弃尾部长为hi - lo的空间。最后调用shrink(),在一定条件下进行缩容。
实现了区间删除后再实现单元素删除就很简单了,只需要在remove(r)中调用remove(r, r+1)即可。
与插入类似,删除算法的时间消耗主要来自于后缀的前移,线性正比于后缀长度,总体不超过$\mathcal O (\underline{}size - hi + 1)$时间。时间复杂度里的+ 1可以理解为删除元素操作需要的时间,这里为更新向量规模。由此可知,区间删除操作需要的时间仅仅取决于后缀中元素的数目,与被删除区间本身的宽度无关。
查找
根据向量的类型,查找的算法有所区别。由于无序向量中没有更多的信息可以借助,在最坏的情况下,只有在访问完所有的元素之后才能得出查找结论。
这里介绍针对无序向量的查找算法:算法从末元素出发,自后向前逐一取出各个元素并与目标元素进行比对,直到发现与之相等者。这种逐个比对的查找方式称作顺序查找。算法如下:
1 | template <typename T> //无序向量的顺序查找:返回最后一个元素e的位置;失败时,返回lo - 1 |
该算法在有多个元素命中时,会返回其中秩最大的元素。另外,查找失败时统一返回lo - 1。当lo为0时,查找失败也不至于导致_elem[]数组越界。因为在第三行中一旦出现lo < hi--,后面的语句也不会执行。
由于该算法是按顺序线性查找的,因此在最坏的情况下查找终止于首元素_elem[lo],运行时间为$\mathcal O (n)$。在最好的情况下,查找命中于末元素_elem[hi - 1],仅需要$\mathcal O (1))$时间。总而言之,该算法的运行时间取决于雷同元素的前缀长度。
对于规模相同、内部组成不同的输入,算法的渐进运行时间却有本质区别,因此此类算法也称作输入敏感的算法。
遍历
遍历算法可以与其他函数联合使用,对向量中对所有元素实施某种统一的操作。针对此类操作,设计接口traverse()如下:
1 | template <typename T> void Vector<T>::traverse ( void ( *visit ) ( T& ) ) //借助函数指针机制 |
该算法设计了两个不同的接口。第一个接口接受一个函数指针,该函数指针指向的函数只有类型为T&的一个参数,将向量中的元素传递给该函数,然后进行进一步的操作。
第二个接口通过函数对象的形式指定具体的遍历操作。所谓函数对象,就是在某个类中重载()操作符,在重载操作符的函数中实现其他复杂操作。这类对象在形式上等效于一个函数接口。
显然,遍历算法的总体时间复杂度为$\mathcal O (n)$。
有序性甄别
在有序向量中,向量的元素按顺序排列,这为许多操作提供了额外的信息,可以简化算法。在考虑是否要使用有序向量的简化算法时,需要首先判断一个向量是否有序。
判断向量有序的方法很简单,也就是顺序扫描整个向量,逐一比较每一对相邻元素。如果两相邻元素出现了逆序的情形,那么向量就是无序的。这个思想与起泡排序中的相同。
唯一化
很多应用中,在进一步处理之前都需要容器中的元素互异。例如,搜索引擎就要求搜索结果中没有重复的条目。向量的唯一化处理,就是剔除向量中的重复元素。
无序向量
1 | template <typename T> Rank Vector<T>::deduplicate() { //删除无序向量中重复元素(高效版) |
该算法的执行思路很简单。在循环的整个过程中,前缀_elem[0, i)中的所有元素均彼此互异。如果在某一步循环中没有找到雷同元素,那么在i++后前缀中依旧没有重复的元素;如果找到了雷同的元素,那么将其删除之后前缀将仍然没有重复的元素。所以当i = _size时,其所有前缀都将不含有重复的元素,也即向量中所有的元素都不重复。
每一步迭代之后,算法中当前元素_elem[i]的后缀都会持续减少。每一步迭代需要的时间主要消耗于find()和remove()两个函数,其中find()需要的时间取决于前缀的长度,remove()需要的时间取决于后缀的长度。因此,每一步迭代需要的时间不会超过$\mathcal O (n)$。又因为该算法经过$\mathcal O (n)$次迭代之后必然终止,因此其总体复杂度为$\mathcal O (n^2)$。
有序向量
为了清除有序向量中的重复元素,可以仿照无序向量的清楚重复元素的算法。对于有序向量的不同之处在于,它内部的重复元素必然前后紧邻。于是我们便不需要像在无序向量中一样调用find()函数,而只需要自前向后地逐一检查各个相邻元素,如果二者雷同则调用remove()函数删除后者,否则转向下一对相邻元素。
该算法运行时间主要消耗于循环部分,一共需要迭代n - 1步。在最坏的情况下,每次都要执行一次remove()操作。又因为remove()操作的复杂度线性正比于被删除元素的后缀长度,因此在最坏情况下有$(n - 2) + (n - 3) + … + 2 + 1 = \mathcal O (n^2)$次操作,与无序向量去重的复杂度相同!完全没有体现有序向量的优势。
上述算法复杂度过高的根源来自于,在对remove()的各次调用中,同一元素可能作为后继多次向前移动,且每次仅移动一个单元。对此的解决办法是,如果有多个雷同的元素,那么就将它们一次性删除好了,这样后缀就可以大跨度地前移。算法实现如下:
1 | template <typename T> Rank Vector<T>::uniquify() { //有序向量重复元素剔除算法(高效版) |
该算法的核心思想就在于:既然各组重复元素必然彼此相邻地构成一个子区间,因此只需要依次保留各个区间的起始元素。从原始向量的角度来看(假设这个算法不进行实际的删除操作),算法中的i与j指向的都是下一对相邻区间的首元素;从修改后的向量的角度来看,i和j分别指向已去重的序列的末尾和即将加入去重序列的新的最后一个元素。下图给出了该算法运行的一个实例:
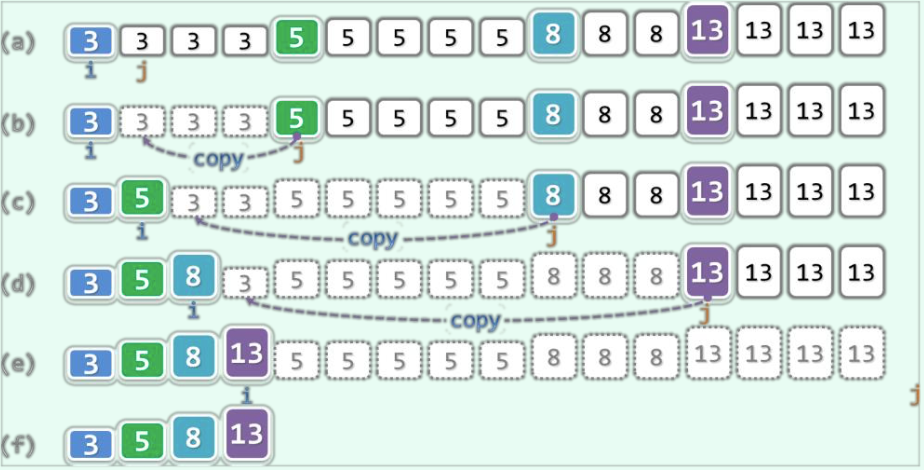
该算法同样直接通过改变_size的值,将尾部多余的元素截除了。i为已去重序列的的最后一个元素的索引,将其加一即可得到去重向量的规模。
上面的算法每经过一次迭代j就加一,直到达到向量的规模n,总共需要迭代n次,时间复杂度为$\mathcal O (n)$。
DSA-4:向量及其接口设计2