
DSA-2:递归
基本概念
递归是函数和过程调用的一种特殊形式,即允许函数进行自我调用。函数的自我(递归)调用过程大致可以概括为:在函数中包含一条或者多条自我调用的语句,待新被调用的函数层层返回后,最终回到起始调用的函数本身。
递归调用相当抽象且简洁,有许多问题都可以准确且简洁地描述为递归形式。比如在操作系统中,文件系统的目录即为递归定义的。具体来说,每个文件系统都有一个顶层目录,其中可以包含若干文件以及下一层的子目录,访问下一层的子目录时就是一个递归的过程。在子目录中还可以有其他子目录,如此递推,直到不含任何下层的子目录。
递归在算法设计中具有重要地位,因此本文将主要介绍递归的不同形式以及递归算法的复杂度分析。
线性递归
数组求和问题亦可以使用递归的办法来解。假设有一个数组有n个元素,当n=0时,和为0;否则,和总是为前n-1个元素加上最后一个元素。示例代码如下:
1 | int sum ( int A[], int n ) { //数组求和算法(线性递归版) |
由之前的分析可以看出,保证递归算法有穷性的基本技巧为:首先判断并处理诸如n=0之类的平凡情况,这种平凡情况被称为递归基。
算法sum()可能朝着更深一层进行自我调用,且每一递归实例对自身的调用最多一次,因而每一层上最多只有一个实例,各个实例构成一个线性的次序关系,所以称为线性递归。在这种形式中,问题总可以分为两个独立的子问题,其中之一对应于单独的某个元素,故可以直接求解,如代码中的A[n-1];另一个对应于剩余部分且结构与原问题相同,如代码中的sum(A. n-1)。
减而治之
所谓减而治之的算法策略,就是每进行一次迭代,待求解问题的规模都会缩减一个常数,直到退化为平凡的小问题。减而治之的策略满足有穷性,因为算法迟早将抵达递归基,此时算法的执行终止。线性递归通常都对应于减而治之的算法策略。
递归分析
递归跟踪图
递归算法的执行过程可以按如下步骤整理为图的形式:
- 算法的每一个递归实例都表示为一个方框,其中注明了该实例调用的参数
- 若实例M调用实例N,则在M与N对应的方框之间添加一条有向连线
下图给出了sum()算法的执行过程。

由图片可看出,算法需要的计算时间等于所有递归实例的创建、执行和销毁所需要的时间总和。递归实例的创建和销毁都由操作系统完成,其时间成本可以近似常数,不会超过递归实例中实质计算步骤所需的时间。将启动递归的语句的执行时间包括进递归实例的创建时间中后,在考虑算法需要的计算时间时只需要统计递归实例中非递归调用所需要的时间。
在sum()算法中,共包括判断、返回、累加三个基本操作,并且对于长度为n的输入,其递归深度为n+1(当n=0时还要再进行一次递归调用,抵达递归基)。因此,整个算法的时间复杂度为$\mathcal O (n)$。
sum()算法使用的空间在创建了最后一个递归实例后达到最大,为所有递归实例各自占用空间之和。又因为每个递归实例中只存放常数个数据,因此算法的空间复杂度同样为$\mathcal O (n)$。
递推方程
递推方程不需要画出具体的调用过程,而是通过对递归模式的数学归纳,导出复杂度定界函数的递推方程(组)及其边界条件,将复杂度分析转化为递归方程(组)的求解。
比如,对于sum()来说,其运行时间总是可以表述为:
- $T(n) = T(n-1) + \mathcal O (1) = T(n-1) + c_1$,其中$n\ne 0$且$c_1$为常数
- $T(0)=\mathcal O(1) = c_2$,其中$n = 0$且$c_2$为常数
连立上面两个方程可以解得:$T(n) = c_1 n + c_2 = \mathcal O (n)$。
多递归基
如果某个问题可能出现多种平凡情况,解决该问题对应的递归算法就应当有多个递归基。
隐式递归基
对于有的算法,其递归基不会显式地写在算法中,如下面的算法。它的功能是把数组的元素全部颠倒。
1 | void reverse ( int* A, int lo, int hi ) { //数组倒置(多递归基递归版) |
在隐式包含的else语句中,含有lo > hi与lo = hi两个递归基,算法运行到此处时便会直接结束。
多向递归
对于有的算法,不但有多个递归基,而且可以有多个递归调用的分支。每一个递归实例虽然可能有多个可能的递归方向,但是只能从中选择其一。因此层次上的递归实例仍然构成一个线性次序关系,依旧属于线性递归。
对于求2的n次幂的问题,一般的方法是要进行n次循环,每循环一次就对待求的数乘2,这种方法的时间复杂度为$\mathcal O (n)$。
另一种方法是,若n的二进制展开式为$b_1b_2b_3…b_k$,则有:$2^n = (…(((1\cdot 2^{b_1})^2 \cdot 2^{b_2})^2 \cdot 2^{b_3})^2…\cdot 2^{b_k})$。若n-1的二进制展开式为$b_1b_2b_3…b_{k-1}$,则有:$2^{n_k} = (2^{n_{k-1}})^2 \cdot 2^{b_k}$。
由此,可以得到:
- 当$b_k = 1$时,有:$power2(n_k) = (power2(n_{k-1}))^2\cdot 2$
- 当$b_k=0$时,有:$power2(n_k) = (power2(n_{k-1})^2\cdot 2$
根据上面的递推式,可以得到算法如下:
1 | inline __int64 sqr ( __int64 a ) { return a * a; } //平方:若是连续执行,很快就会数值溢出! |
对于输入的参数为奇数或者偶数的两种可能,该算法有两种不同的递归方向。由于递归方向只能二选一,因此仍然属于线性递归。由于输入n的二进制数的位数为$r = 1 + \lfloor log_2n\rfloor$,算法最多执行$r + 1$次递归(此时n为奇数),故该算法的时间复杂度为$\mathcal O (logn) = \mathcal O (r)$。
递归消除
递归调用虽然简洁优雅,但是相比于同一算法的迭代版本,它会因为创建、维护、销毁递归实例而消耗更多的时间和空间。对于某些类型的递归算法,可以将其改写为迭代的形式以提高性能。
尾递归
在线性递归算法中,如果递归调用在递归实例中刚好以最后一步操作的形式出现,则称之为尾递归。这种类型的递归算法可以简单地转换为等效的迭代版本。比如对于本文中的reverse()算法,就可以将其转换为如下的迭代形式:
1 | void reverse ( int* A, int lo, int hi ) { //数组倒置(规范整理之后的迭代版) |
需要注意的是,递归语句出现在代码的最后一行并不一定就是尾递归。严格来说,只有算法在除递归基外的任一实例都终止于这一调用时,才属于尾递归。换句话说,算法的最后操作仅为递归调用函数本身,不包括其他操作。例如,sum()算法中的最后一行的代码是递归调用,但是它并不是尾递归。
二分递归
分而治之
分而治之就是将一个规模较大的问题分解为若干个规模更小的,与原问题本质相同的问题,再利用递归机制分别求解。这种分解过程持续进行,直到问题规模缩减至平凡情况。
多路递归与二分递归
在分而治之的策略中,每一个递归实例都有可能做多次递归,因而称为多路递归。在多路递归中,通常又是将原问题一分为二,故称之为二分递归。
数组求和
老生常谈的数组求和问题也可以通过二分递归的模式解决。该算法的思路是:以居中的元素为界将数组一分为二,递归地对子数组分别求和,最后再将子数组之和相加即得到原数组的总和。代码如下:
1 | int sum ( int A[], int lo, int hi ) { //数组求和算法(二分递归版,入口为sum(A, 0, n)) |
这个算法显然是正确的。下面给出了使用该算法对数组A中索引为[0, 8)的元素进行求和的递归跟踪图。
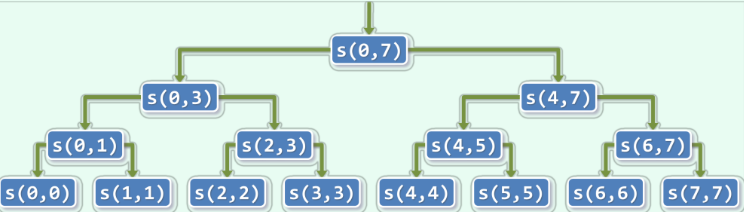
由图可知,该算法的递归实例形成了一个二叉树形式的层次结构,沿着这个层次每下降一层,每个递归实例sum(A, lo, hi)都分裂为一对更小的实例sum(A, lo, mi)与sum(A, mi+1, hi)。
为了分析其复杂度,出于方便起见,就考察数组元素$n = 2^m$个时的情形。算法启动后经过$m = \lceil log_2 n\rceil$层递归调用,数组区间长度首次缩减为1,到达递归基,在返回后进入另外的一个递归分支。由此可知,该算法的递归深度不会超过$1 + log_2n$(当$n$为二的幂次时,递归深度恰好为$log_2 n$)。由于每个递归实例只需要常数空间,因此除去输入占用的空间外,该算法总共只需要$\mathcal O (logn)$的附加空间。相比于先前使用线性递归方法的数组求和算法(需要$\mathcal O (n)$的附加空间),性能有了不小的提升。
在时间复杂度上,由于每个递归实例的计算都需要常数时间,且有$2n - 1$个递归实例,故算法的运行时间为$\mathcal O (n)$。
分而治之的局限性
分而治之策略的消耗主要来自划分子问题与合并子解答两个方面。分治策略的高效性依赖于子问题之间的相互独立。下面给出了一个不宜采用分之策略的反例。
考察求斐波那契数列第n项fib(n)的问题。斐波那契数列的递归形式的定义为:
- 当$n\le 1$时,$fib(n) = n$
- 当$n\ge 2$时,$fib(n) = fib(n-1) + fib(n-2)$
据此可直接得到求斐波那契数的算法的二分递归版本:
1 | __int64 fib ( int n ) { //计算Fibonacci数列的第n项(二分递归版):O(2^n) |
这个算法虽然看上去很美好,实际上它需要运行$\mathcal O(2^n)$时间才能计算出结果,这是因为在计算过程中出现的递归实例的重复次数过多。
消除重复的递归实例
为了消除重复的实例,我们可以用空间换时间:通过一定的辅助空间,在各子问题求解之后及时记录下其对应的解答。
具体来说有两种方法:
- 制表(或记忆)策略:从原问题出发自上而下,每遇到一个子问题就先查验它是否已经计算过,若是则直接提取解答
- 动态规划策略:从递归基出发,自下而上递推求出问题的解,最后到达原问题的解
下面的算法使用了制表策略来优化先前求斐波那契数的二分递归算法:
1 | __int64 fib ( int n, __int64& prev ) { //计算Fibonacci数列第n项(线性递归版):入口形式fib(n, prev) |
注意fib()函数的第二个参数为变量的引用。在到达递归基时,函数的第二行通过引用,将处于递归基的递归实例下一层的递归实例中的prevPrev的值设为1,该变量即对应的是$fib(-1)$。在其它通常情况下,prevPrev对应的即为$fib(n-2)$。该函数在第5行通过引用,在其下一层递归实例中将再下一层的递归实例的返回值传给了当前的递归实例。
该算法结构呈线性递归模式,递归深度正比于输入$n$,共计出现$\mathcal O (n)$个递归实例(需要$\mathcal O (n)$的附加空间),累计耗时不超过$\mathcal O (n)$。
还可以使用动态规划规划算法解决该问题。
在算法抵达递归基之后的返回过程中,每向上返回一层,以下各层解答均不需要继续保留。若将以上逐层返回的过程,等效地视作从递归基出发,按照规模自小到大求解各子问题的过程,即可采用动态规划的策略:
1 | __int64 fibI ( int n ) { //计算Fibonacci数列的第n项(迭代版):O(n) |
该算法使用f和g保存当前的一对相邻的斐波那契数。代码第三行中g += f计算出了$fib(n)$;f = g - f计算出了$f(n-1)$,为下一步计算做好了准备。在下一步迭代中,原先的$fib(n)$和$fib(n-1)$分别变成了$fib(n-1)$与$fib(n-2)$,整个算法得以持续进行下去,直到达到问题的原规模(n自减至0)。
该算法的时间复杂度为$\mathcal O (n)$,同时也只需要常数规模的附加空间。