Summary of Reinforcement Learning 1
Preface
This blog is the first one of my series of blogs that summary the key points of reinforcement learning, other blogs will be updated recently according to my learning progress.
These series of blogs of mine are mostly based on the following works and I’m really grateful to the contributors:
- Online courses of Stanford University CS234: Reinforcement Learning, Emma Brunskill and lecture notes.
- Blogs of 从流域到海域.
- Blogs of 叶强.
If you find any mistake in my articles, please feel free to tell me in comments.
What is reinforcement learning (RL)?
RL is a kind of machine learning method that mainly focuses on the interaction between the agent (subject) and the model (environment, world). Through this interaction, the agent can gain experience and then have a better performance in some specific aspects. For example, a robot player can get a high score in a game after being trained by using RL method, or we can make the autopilot of the car to control it keep its lane and drive to the destination smoothly without any collision.
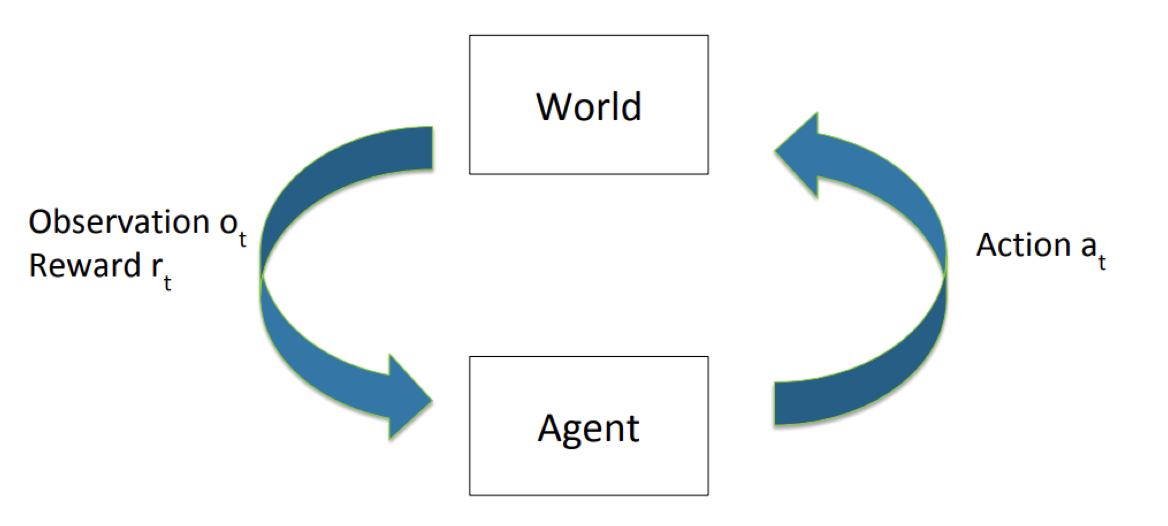
A RL agent may interact with the world, and then recieve some feedback signal for each interaction. By jduging whether the feedback signal is good (beneficial to the agent’s desire performance) or not, the agent can then change its way interacting with the world (make better decisions) in order to reach the best performance. By accumulating these experiences, the agent can become more and more “smarter” and has a better performance.
Some basic notions of RL
Because in the real world, we make decisions in a sequence in a period. Therefore, we need to introduce “time” to clearly indicate the quantities related to the agent at the specific position on the time axis. The notation with subscript “t” means time it is in a time sequence.
- Agent: The subject of RL, it is agent that interact with the world.
- Model: The world, the environment, the agent stays in the model.
- Reward: $ {r_t} $ , the feedback signal from the model, agent recieves the reward. The reward can have different values according to the different states of the agent.
- State: ${s_t}$ , the state of the agent. The state can be either finite or infinite, and it is set by people.
- Action: ${a_t}$ , the movement of the agent in the model, actions are different under different states.
- Observation: ${o_t}$ , the agent need to observe its state and determine the reward.
- History: a sequence of action, reward, observation, which is: $h_t=(a_1,o_1,r_1,…,a_t,o_t,r_t)$.
- Sequential Decision Making: make decision base on the history, that is: $a_{t+1}=f(h_t)$.
Figure 1.1 shows how an agent interact with its world.
How to model the world?
Markov Property
$P(s_{t+1}|s_t,a_t,…,s_1,a_1)=P(s_{t+1}|s_t,a_t)$
Left-hand side is called the transition dynamics of the world, whcih means the probability distribution over $S$. In RL, we often use this assumption.
A model consists of the two elements below.
Transition dynamics $P(s_{t+1}|s_t,a_t)$
The probability of a specific state in the next timestep. Because an agent always has many states, $P$ is often a matrix. The dimension of $P$ denpends on the dimension of the state space.
Reward function $R(s,a)$
Usually, we consider the reward $r_t$ to be received on the transition between states, $s_t\rightarrow{s_{t+1}}$. A reward function is used to predict rewards, which can be written in the form $R(s,a)=\Bbb E[r_t|s_t=s,a_t=a]$.
How to make a RL agent?
Let the agent state be a function of the history, $s_t^a=g(h_t)$.
An agent often consists the three elements below.
Policy $\pi(a_t|s_a^t)$
Policy is a mapping from the state to an action, which means we can determine the action through the policy if we know the state. Please notice that the policy we mention here is stochastic. When the agent want to take an action and $\pi$ is stochastic, it picks action $a\in A$ with probability
$P(a_t=a)=\pi(a|s_t^a)$.
Value function $V^\pi$
If we have discount factor $\gamma\in [0,1]$, which is used to weigh immediate rewards versus delayed rewards, value function is an expected sum of discounted rewards
$V^\pi=\Bbb E_\pi[r_t+\gamma r_{t+1}+\gamma ^2 r_{t+2}+…|s_t=s]$.
Model
The agent in RL may have a model. I have introduced how to make a model in section 3.
Three questions we are facing
Do we need exploration or exploitation?
In RL, the agent must be able to optimize its actions to maximize the reward signal it receives. We have 2 ways to achieve this target, the first is to let the agent exploit what it already knows, the second is to explore the world where is unknown for the agent. This leads to a trade-off between exploration and exploitation.
Can the agent generalize its experience?
In actual world, the agent often has infinite states. However, it is impossible for us to include all of them in RL. Can the agent learn whether some actions are good or bad in previously unseen states?
Delayed consequences
The action executed by the agent may let it recieve high reward at present state. However, this action may have negative effects in the future. Or we can also ask, if the rewards are caused by the action the agent just took or because of the action taken much earlier?
What’s next?
Now we have known the basic frame and its components of reinforcement learning. But what is the exact form of the transition dynamics, reward function, policy, value function? And what’s the relationship between these functions? How can I use these functions to make an agent? We will discuss these questions in the next chapter.
Summary of Reinforcement Learning 1